CHAPTER 35
PIGGY-BACKED DATABASES
All disk-resident data exists in a file called the VM (Virtual Memory)
file. We consider here two topics. The first regards a use of
~multiple VM files. The second focusses on garbage collection for
VM file(s).
The use of multiple VM files allows one to keep not only a completely
up to date database, but several older versions of the database as
well. Keeping older versions of the database fascilitates going back
to an earlier state of affairs, in case something has gone wrong
(e.g., a machine crash). Earlier versions are useful also if one
wishes to compare a computation rendered upon the latest database and
earler versions.
Multiple versions of a database can be represented efficiently via
several files. Each VM file, a version of the database, is based on
a previous VM file, an earlier version of the database. Efficient
representation occurs by representing in the new VM file only the
~differences between this database and the earlier version.
This way, the entirety of the database is spread over several VM
files, with little redundancy across the files.
As databases evolve, some data in them may cease to be referenced.
Reclaiming the space taken by unreachable data is referred as
~garbage ~collecting ~the ~VM ~files. The entire database can be
garbage collected, which for a 150 megabyte database can take almost
two hours elapsed time. In practice, such ~full garbage collections
have occured about once every six months.
An alternative to a full garbage collection is to garbage collect only
data recently contributed to the database. Such ~partial garbage
collections might occur once a week, for an active week of software
development. These run relatively quickly, spending 15 minutes (about
once a week), or a half an hour (once a month). This form of partial
garbage collection is sometimes refered to as ~ephemeral garbage
collection.
35.1
Piggy-Backed VM Files
Each session of ICL starts off with a database to read, a VM file.
During the session, a ~new VM file is written. Once the session ends,
the new VM file becomes the up to date database.
The new VM file refers internally to the old VM file, the one present
at the start of the session. Of course, the new VM file is relatively
compact, as it contains only the ~differences between the new and old
VM databases.
Thus, each ICL session begins with two questions: What database shall
be ~read, and what new VM file shall be ~written? The new VM file
will hold all the updates to the database made by this session.
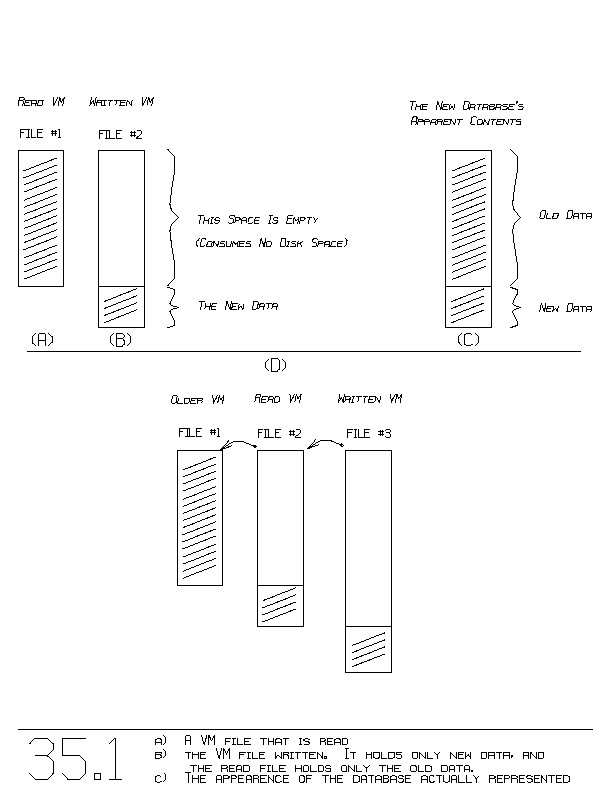 Figure 35.1(a and b) show the read VM file and the written VM file.
This figure is slightly over simplified in that we assume no old data
are modified. That is, we assume this session contributes only new
data.
The figure shows that the written VM file is empty where the old
database resides. The new, complete database is seen by merging the
two VM files, as shown in part (c) of the figure.
The written VM file contains the name of the read VM. Thus, later,
when we read the new VM file just now written, it will present the
entire database. The new VM file in conjunction with the old VM
file(s) make up the new database. Figure 35.1(d) shows ~three VM files
piggy-backed upon one another. This is the situation when the written
VM file (in part (b)) becomes the read VM for a later session.
File #3 contains the newest data along with the file name "file2".
Similarly, file2 contains slightly older data along with the file
name "file1". File1 contains the old database. This chain of files
is called a ~piggy-back chain. File(K) is piggy-backed off of
file(K-1).
---------------- Parentheses in previous paragraph mean subscripting! ---
BOX: How do multiple VM files provide efficiently for the
BOX: maintenance of both old and new databases?
BOX:
BOX: Where does all ~written data go?
BOX:
BOX: What to questions are asked upon starting up ICL?
35.2
The Map Table - Which Diskette Is In Which File?
Recall that a disk-resident structure resides in one ~diskette.
A diskette is logically a contiguous piece of disk. Input/output
to and from the database occurs one diskette at a time.
Each diskette resides in ~some VM file. All diskettes ~written during
this session go into the written VM file. Diskettes from the old
database reside in the older VM files, the read VM file and those
earlier VM files off of which the read VM is piggy-backed.
Figure 35.1(a and b) show the read VM file and the written VM file.
This figure is slightly over simplified in that we assume no old data
are modified. That is, we assume this session contributes only new
data.
The figure shows that the written VM file is empty where the old
database resides. The new, complete database is seen by merging the
two VM files, as shown in part (c) of the figure.
The written VM file contains the name of the read VM. Thus, later,
when we read the new VM file just now written, it will present the
entire database. The new VM file in conjunction with the old VM
file(s) make up the new database. Figure 35.1(d) shows ~three VM files
piggy-backed upon one another. This is the situation when the written
VM file (in part (b)) becomes the read VM for a later session.
File #3 contains the newest data along with the file name "file2".
Similarly, file2 contains slightly older data along with the file
name "file1". File1 contains the old database. This chain of files
is called a ~piggy-back chain. File(K) is piggy-backed off of
file(K-1).
---------------- Parentheses in previous paragraph mean subscripting! ---
BOX: How do multiple VM files provide efficiently for the
BOX: maintenance of both old and new databases?
BOX:
BOX: Where does all ~written data go?
BOX:
BOX: What to questions are asked upon starting up ICL?
35.2
The Map Table - Which Diskette Is In Which File?
Recall that a disk-resident structure resides in one ~diskette.
A diskette is logically a contiguous piece of disk. Input/output
to and from the database occurs one diskette at a time.
Each diskette resides in ~some VM file. All diskettes ~written during
this session go into the written VM file. Diskettes from the old
database reside in the older VM files, the read VM file and those
earlier VM files off of which the read VM is piggy-backed.
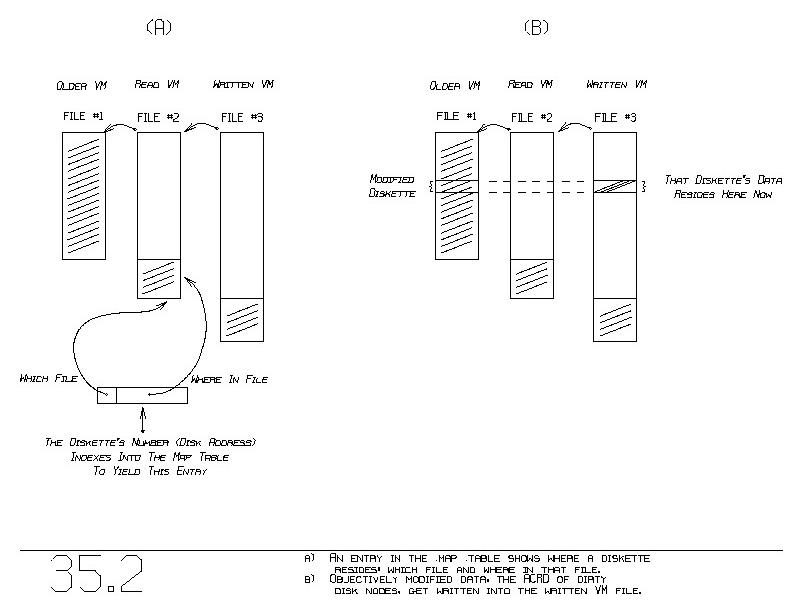 Each diskette has a unique integer, which we have called the ~disk
~address. In main memory (core), a map table is kept, having
one entry per diskette. Given a diskette's number, we index into that
table to acquire two essential data. The first datum indicates in
~which VM file the diskette really resides. The second datum tells
~where in the file the diskette begins (figure 35.2).
One might imagine that one could deduce the ~which ~file question
based on the starting address of the diskette. Low addresses imply
the old file, and a high address implies the new file. However,
figure 35.2(b) shows a phenomenon not yet considered.
When one applies objective modification (using the @-operator), we say
that any structure containing that modified block is ~dirty.
Dirtiness propogates out to the disk, in that the structure will be
rewritten to disk. All data written to disk always goes into the one
written VM file.
It is possible therefore that one might dirty a structure taken from
the old database, as shown in figure 35.2(b). When that dirty
structure is written back out to disk, it goes into the written VM
file (at the right in the figure). Here, we have a diskette with a
low address residing in the written VM file.
Once the writting is done, we modify the map table. That diskette had
resided in the old VM file, and the map table entry for this
diskette indicated so. Now, we make that diskette's entry indicate the
new file. The diskette's number (disk address) is not changed, only
its entry in the map table.
35.2.1
Loading The Map Table
Each VM file contains its own version of the map table. For each
diskette it contains, it has an entry in the table for that
diskette.
When a session starts, the read VM file, and all the older files off
of which it is piggy-backed, are opened. The map table from the
~oldest VM file is loaded first into the core-resident map table.
Then the ~second oldest file's map table is loaded. If that
second oldest file has an entry of a diskette that was also represented
in the oldest VM file, then naturally the newer file's entry overwrites
the entry left by the oldest VM file. Thus, the entry for that
diskette is most up to date, pointing to the newer file.
After the second oldest file's map table is loaded, we go on
to load the map table from the third oldest VM file. We procede
this way for each file, including the newest old VM file, the ~read
VM file. This process leaves in the map table the ~latest
rendition for any diskette.
We have thus accounted for all data resident in the original
database's VM files.
As new diskettes are created, entries are introduced at the end of the
map table. The indices for those new diskettes are allocated
starting from one beyond the highest diskette number in the read
database.
BOX: What's in the map table?
BOX:
BOX: How is it that the map table winds up referring to the
BOX: latest version of a diskette?
35.3
VM-File Garbage Collection
Data in VM files can cease to be referenced, as can be the case for
memory resident data. Garbage collection reclaims all that space.
The same can be done for VM files.
35.3.1
The Root In A VM File
Recall that our garbage collector for main memory ~marked all data
reachable by following all pointers, starting from what we called the
~roots. In main memory, the roots were all program variables.
In a VM file, there is one root, diskette #1. It contains a
BASIC_PROCESS. Whenever an ICL session starts, the old database is
read. The BASIC_PROCESS represented in diskette #1 is loaded and
invoked. That BASIC_PROCESS can do a lot of things. Usually, it
simply calls a function that delivers interactive ICL. Whatever it
does, when it finishes executing, the session is terminated, leaving
a valid written VM file. During the session, another BASIC_PROCESS
may be assigned to diskette #1 if desired.
That BASIC_PROCESS can hold onto a variety of data, via its square-
bracket context (Sections 23.6.1 and 23.6.3). It may hold onto a
symbol table, and/or a hierarchical file system implemented entirely
within the VM file(s).
35.3.2
Full Garbage Collection
The entirety of a database can be garbage collected. The result is
one, big VM file, that replaces all the piggy-backed VM files making
up the database. The result, of course, contains no garbage, only
reachable data. Garbage collection occurs by copying reachable data
from the old database into a new VM file.
A special table is built in main memory, called the translation
table. Any existing diskette's number indexes into the table, and out
comes a new diskette number. This maps diskette numbers from the old
database into new, contiguous numbers for the new VM file.
35.3.2.1
Entries Indicate Whether A Diskette Still Needs To Be Copied
Each entry in the table can be ~positive or ~negative. A negative
value indicates that this (reachable) diskette as yet still needs to
be copied into the new VM file. Once that diskette is copied, its
entry is made positive.
A zero in the table indicates that this diskette hasn't even been
encountered yet.
Initially, diskette #1 is the only non-zero entry in the table. The
entry is negative so as to indicate that the diskette needs to be
copied into the new VM file.
The table is scanned from the bottom (diskette #1) to the top. Each
negative entry encountered causes a copy operation.
An ~index into the table for an entry denotes a diskette from the old
database. If the indexed entry is negative, we read that diskette
as though it were being swapped into core. It is simultaneously
written to the new database, as a new diskette whose number is taken
from that entry in the table.
35.3.2.2
Disk Nodes Encountered During A Copy Operation
Each disk node encountered ~during ~the ~copy affects our table.
The disk node's (old) diskette number naturally indexes into the table.
If that entry is zero, then this (old) diskette has not been
encountered before. We therefore allocate a new diskette number
for that diskette, a diskette number for use within the new database.
The negative of that new diskette number is put into that entry. The
negativeness indicates that this referenced diskette must yet be
copied.
The disk node's (old) diskette number is translated before it is
written out as part of the copy operation. The (old) diskette
number's entry in the table contains the new diskette number for that
diskette. (The absolute value of that entry is written out).
Thus, during a diskette's copy operation, all disk nodes (diskette
numbers) encountered get a non-zero entry into the special table.
35.3.2.3
Setting A Non-Zero Entry Corresponds To ~Marking
We render non-zero an entry when its corresponding diskette is
~encountered. This corresponds to ~marking the diskette.
All non-zero (marked) entries will wind up copied. This assures that
all reachable diskettes will be copied into the new database. As each
is copied, other (referenced) diskettes will be marked, i.e. given
negative entries in the table if not already non-zero).
Upon completing each copy, its entry in the table is
rendered positive, indicating that it has been copied. When there are
no more negative entries, the VM garbage collection is complete. All
reachable diskettes have been copied.
BOX: What is the root in a VM file?
BOX:
BOX: What is the difference between a positive and negative
BOX: value in the translation table?
BOX:
BOX: What effect on the table corresponds to marking?
BOX:
BOX: When doe the VM garbage collection terminate?
35.3.3
Partial Or Ephemeral Garbage Collection
Each diskette has a unique integer, which we have called the ~disk
~address. In main memory (core), a map table is kept, having
one entry per diskette. Given a diskette's number, we index into that
table to acquire two essential data. The first datum indicates in
~which VM file the diskette really resides. The second datum tells
~where in the file the diskette begins (figure 35.2).
One might imagine that one could deduce the ~which ~file question
based on the starting address of the diskette. Low addresses imply
the old file, and a high address implies the new file. However,
figure 35.2(b) shows a phenomenon not yet considered.
When one applies objective modification (using the @-operator), we say
that any structure containing that modified block is ~dirty.
Dirtiness propogates out to the disk, in that the structure will be
rewritten to disk. All data written to disk always goes into the one
written VM file.
It is possible therefore that one might dirty a structure taken from
the old database, as shown in figure 35.2(b). When that dirty
structure is written back out to disk, it goes into the written VM
file (at the right in the figure). Here, we have a diskette with a
low address residing in the written VM file.
Once the writting is done, we modify the map table. That diskette had
resided in the old VM file, and the map table entry for this
diskette indicated so. Now, we make that diskette's entry indicate the
new file. The diskette's number (disk address) is not changed, only
its entry in the map table.
35.2.1
Loading The Map Table
Each VM file contains its own version of the map table. For each
diskette it contains, it has an entry in the table for that
diskette.
When a session starts, the read VM file, and all the older files off
of which it is piggy-backed, are opened. The map table from the
~oldest VM file is loaded first into the core-resident map table.
Then the ~second oldest file's map table is loaded. If that
second oldest file has an entry of a diskette that was also represented
in the oldest VM file, then naturally the newer file's entry overwrites
the entry left by the oldest VM file. Thus, the entry for that
diskette is most up to date, pointing to the newer file.
After the second oldest file's map table is loaded, we go on
to load the map table from the third oldest VM file. We procede
this way for each file, including the newest old VM file, the ~read
VM file. This process leaves in the map table the ~latest
rendition for any diskette.
We have thus accounted for all data resident in the original
database's VM files.
As new diskettes are created, entries are introduced at the end of the
map table. The indices for those new diskettes are allocated
starting from one beyond the highest diskette number in the read
database.
BOX: What's in the map table?
BOX:
BOX: How is it that the map table winds up referring to the
BOX: latest version of a diskette?
35.3
VM-File Garbage Collection
Data in VM files can cease to be referenced, as can be the case for
memory resident data. Garbage collection reclaims all that space.
The same can be done for VM files.
35.3.1
The Root In A VM File
Recall that our garbage collector for main memory ~marked all data
reachable by following all pointers, starting from what we called the
~roots. In main memory, the roots were all program variables.
In a VM file, there is one root, diskette #1. It contains a
BASIC_PROCESS. Whenever an ICL session starts, the old database is
read. The BASIC_PROCESS represented in diskette #1 is loaded and
invoked. That BASIC_PROCESS can do a lot of things. Usually, it
simply calls a function that delivers interactive ICL. Whatever it
does, when it finishes executing, the session is terminated, leaving
a valid written VM file. During the session, another BASIC_PROCESS
may be assigned to diskette #1 if desired.
That BASIC_PROCESS can hold onto a variety of data, via its square-
bracket context (Sections 23.6.1 and 23.6.3). It may hold onto a
symbol table, and/or a hierarchical file system implemented entirely
within the VM file(s).
35.3.2
Full Garbage Collection
The entirety of a database can be garbage collected. The result is
one, big VM file, that replaces all the piggy-backed VM files making
up the database. The result, of course, contains no garbage, only
reachable data. Garbage collection occurs by copying reachable data
from the old database into a new VM file.
A special table is built in main memory, called the translation
table. Any existing diskette's number indexes into the table, and out
comes a new diskette number. This maps diskette numbers from the old
database into new, contiguous numbers for the new VM file.
35.3.2.1
Entries Indicate Whether A Diskette Still Needs To Be Copied
Each entry in the table can be ~positive or ~negative. A negative
value indicates that this (reachable) diskette as yet still needs to
be copied into the new VM file. Once that diskette is copied, its
entry is made positive.
A zero in the table indicates that this diskette hasn't even been
encountered yet.
Initially, diskette #1 is the only non-zero entry in the table. The
entry is negative so as to indicate that the diskette needs to be
copied into the new VM file.
The table is scanned from the bottom (diskette #1) to the top. Each
negative entry encountered causes a copy operation.
An ~index into the table for an entry denotes a diskette from the old
database. If the indexed entry is negative, we read that diskette
as though it were being swapped into core. It is simultaneously
written to the new database, as a new diskette whose number is taken
from that entry in the table.
35.3.2.2
Disk Nodes Encountered During A Copy Operation
Each disk node encountered ~during ~the ~copy affects our table.
The disk node's (old) diskette number naturally indexes into the table.
If that entry is zero, then this (old) diskette has not been
encountered before. We therefore allocate a new diskette number
for that diskette, a diskette number for use within the new database.
The negative of that new diskette number is put into that entry. The
negativeness indicates that this referenced diskette must yet be
copied.
The disk node's (old) diskette number is translated before it is
written out as part of the copy operation. The (old) diskette
number's entry in the table contains the new diskette number for that
diskette. (The absolute value of that entry is written out).
Thus, during a diskette's copy operation, all disk nodes (diskette
numbers) encountered get a non-zero entry into the special table.
35.3.2.3
Setting A Non-Zero Entry Corresponds To ~Marking
We render non-zero an entry when its corresponding diskette is
~encountered. This corresponds to ~marking the diskette.
All non-zero (marked) entries will wind up copied. This assures that
all reachable diskettes will be copied into the new database. As each
is copied, other (referenced) diskettes will be marked, i.e. given
negative entries in the table if not already non-zero).
Upon completing each copy, its entry in the table is
rendered positive, indicating that it has been copied. When there are
no more negative entries, the VM garbage collection is complete. All
reachable diskettes have been copied.
BOX: What is the root in a VM file?
BOX:
BOX: What is the difference between a positive and negative
BOX: value in the translation table?
BOX:
BOX: What effect on the table corresponds to marking?
BOX:
BOX: When doe the VM garbage collection terminate?
35.3.3
Partial Or Ephemeral Garbage Collection
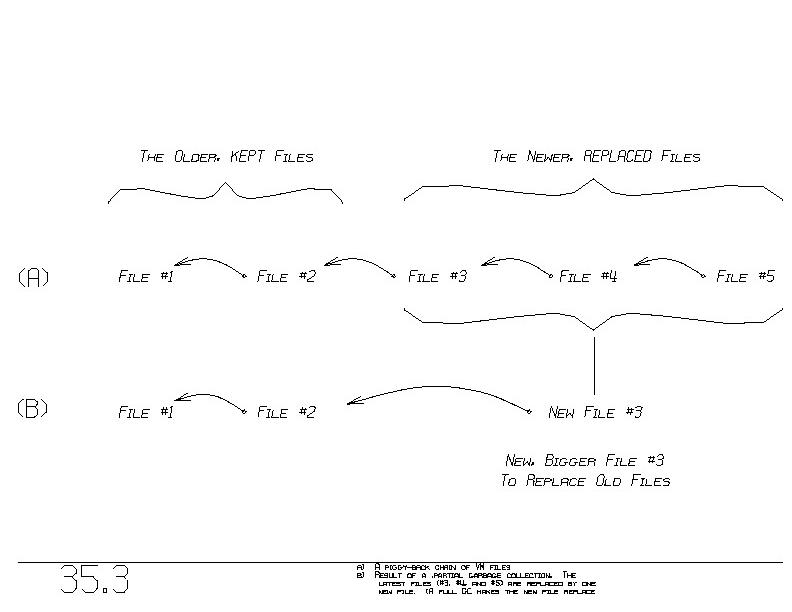 Figure 35.3(a) shows a piggy-back chain. The oldest file appears on
the left and the newest file on the right. A full garbage collection
would produce one big file that replaces all five files shown.
However, it is possible to save time and simultaneously keep ~some
older versions of the database. Figure 35.3(b) shows the result of a
partial garbage collection. The three ~newest files are replaced by
one newer file. Files #1 and #2 continue to be in the piggy-back
chain.
The reduction in cost relative to a full GC is significant. A full GC
takes time proportional to the size of the entire database,
approximately the sum of the sizes of all the files. When we collapse
only files 3, 4, and 5, into one new file, the cost is proportional
to the sum of the sizes of only those files.
In our experience with large VLSI and program databases, the size of
the oldest file (file #1) might be 150 megabytes, the second file might
be 25 megabytes, and files further up the chain might be five or fewer
megabytes. The sum of the sizes of files 3, 4, and 5 is miniscule (5
megabytes) compared to the whole database (150 megabytes). Paying a
GC cost proportional to only the sum of the sizes of the little files
is a great savings.
Partial garbage collection collapses the newest (rightmost) files into
one, garbage collected replacement file (figure 35.3(b)). A partial GC
takes as its parameter the number of files to be kept (files on the
left). The files to be replaced are called the newer, ~replaced
~files. The others are called the older, ~kept files.
35.3.3.1
How Partial Garbage Collection Procedes
Partial garbage collection occurs just like a full garbage collection
except for two things. First, when chasing pointers (diskette numbers)
we ~never pursue any pointers that lead into the kept files. This
limits our travels to only the ~replaced ~files. This is what limits
the cost to be proportional to the replaced files' sizes.
The second difference is this. We follow all pointers by starting
at the root (diskette #1) as usual, but we introduce ~more ~roots as
well.
Consider each diskette in the replaced files which eclipses
older versions of that diskette in the kept files (e.g.,
figure 35.2(b)). Each of those diskettes is taken unconditionally as a
new root.
Why can we avoid travelling thru the older, kept files? Might we not
miss pointers from ~there into the replaced files?
That is, diskettes in the older, kept files might point to diskettes
in the newer, replaced files. If we don't see those references from
the older, kept files, won't we accidently release as garbage those
referenced, newer diskettes in the replaced files?
In Section 10.2.5 we discovered that in the absence of
objective modification (@), newer blocks can point only to older
blocks, and ~not vice versa. To make an old block point to a newer
block, that older block had to have been modified objectively.
We can deduce the following: Any path of pointers that dives into the
older, kept files will never re-emerge in the newer, replaced files,
~except via diskttes that were modified objectively. ~All such
modified diskettes appear in the newer, replaced VM files!
We avoid pursuits in the older, kept files by taking a conservative
stand. We take as roots ~all such modified diskettes, ~all diskettes
copied on write to the newer, replaced files. This way, we
continue pursuit from all ~possible diskettes that ~might be arrived
at via pursuits thru the kept files.
35.3.3.2
The Retention Of A Little Extra Garbage
This conservative approach assumes that ~all diskettes copied on write
are ~in ~use. A less conservative approach would be to discover which
~subset of those diskettes are really in use. However, that would
require exploration thru the older, kept files. Our conservative
approach relieves that cost, with the possibility of keeping ~more
diskettes than are actually in use.
Thus partial GCs may retain some garbage. In practice, this extra
retention has made little difference. As mentioned earlier, only once
every six months to a year has a full (2 hour) GC been helpful.
Of course, a full GC makes no comprimizes, and retains no extra
garbage, because ~all files are replaced files. All pursuits are
taken and only reachable diskettes, no matter where they reside, will
be copied into the new VM file.
35.3.4
The Evolution Of Piggy-Backed VM Files
Figure 35.3(a) shows a piggy-back chain. The oldest file appears on
the left and the newest file on the right. A full garbage collection
would produce one big file that replaces all five files shown.
However, it is possible to save time and simultaneously keep ~some
older versions of the database. Figure 35.3(b) shows the result of a
partial garbage collection. The three ~newest files are replaced by
one newer file. Files #1 and #2 continue to be in the piggy-back
chain.
The reduction in cost relative to a full GC is significant. A full GC
takes time proportional to the size of the entire database,
approximately the sum of the sizes of all the files. When we collapse
only files 3, 4, and 5, into one new file, the cost is proportional
to the sum of the sizes of only those files.
In our experience with large VLSI and program databases, the size of
the oldest file (file #1) might be 150 megabytes, the second file might
be 25 megabytes, and files further up the chain might be five or fewer
megabytes. The sum of the sizes of files 3, 4, and 5 is miniscule (5
megabytes) compared to the whole database (150 megabytes). Paying a
GC cost proportional to only the sum of the sizes of the little files
is a great savings.
Partial garbage collection collapses the newest (rightmost) files into
one, garbage collected replacement file (figure 35.3(b)). A partial GC
takes as its parameter the number of files to be kept (files on the
left). The files to be replaced are called the newer, ~replaced
~files. The others are called the older, ~kept files.
35.3.3.1
How Partial Garbage Collection Procedes
Partial garbage collection occurs just like a full garbage collection
except for two things. First, when chasing pointers (diskette numbers)
we ~never pursue any pointers that lead into the kept files. This
limits our travels to only the ~replaced ~files. This is what limits
the cost to be proportional to the replaced files' sizes.
The second difference is this. We follow all pointers by starting
at the root (diskette #1) as usual, but we introduce ~more ~roots as
well.
Consider each diskette in the replaced files which eclipses
older versions of that diskette in the kept files (e.g.,
figure 35.2(b)). Each of those diskettes is taken unconditionally as a
new root.
Why can we avoid travelling thru the older, kept files? Might we not
miss pointers from ~there into the replaced files?
That is, diskettes in the older, kept files might point to diskettes
in the newer, replaced files. If we don't see those references from
the older, kept files, won't we accidently release as garbage those
referenced, newer diskettes in the replaced files?
In Section 10.2.5 we discovered that in the absence of
objective modification (@), newer blocks can point only to older
blocks, and ~not vice versa. To make an old block point to a newer
block, that older block had to have been modified objectively.
We can deduce the following: Any path of pointers that dives into the
older, kept files will never re-emerge in the newer, replaced files,
~except via diskttes that were modified objectively. ~All such
modified diskettes appear in the newer, replaced VM files!
We avoid pursuits in the older, kept files by taking a conservative
stand. We take as roots ~all such modified diskettes, ~all diskettes
copied on write to the newer, replaced files. This way, we
continue pursuit from all ~possible diskettes that ~might be arrived
at via pursuits thru the kept files.
35.3.3.2
The Retention Of A Little Extra Garbage
This conservative approach assumes that ~all diskettes copied on write
are ~in ~use. A less conservative approach would be to discover which
~subset of those diskettes are really in use. However, that would
require exploration thru the older, kept files. Our conservative
approach relieves that cost, with the possibility of keeping ~more
diskettes than are actually in use.
Thus partial GCs may retain some garbage. In practice, this extra
retention has made little difference. As mentioned earlier, only once
every six months to a year has a full (2 hour) GC been helpful.
Of course, a full GC makes no comprimizes, and retains no extra
garbage, because ~all files are replaced files. All pursuits are
taken and only reachable diskettes, no matter where they reside, will
be copied into the new VM file.
35.3.4
The Evolution Of Piggy-Backed VM Files
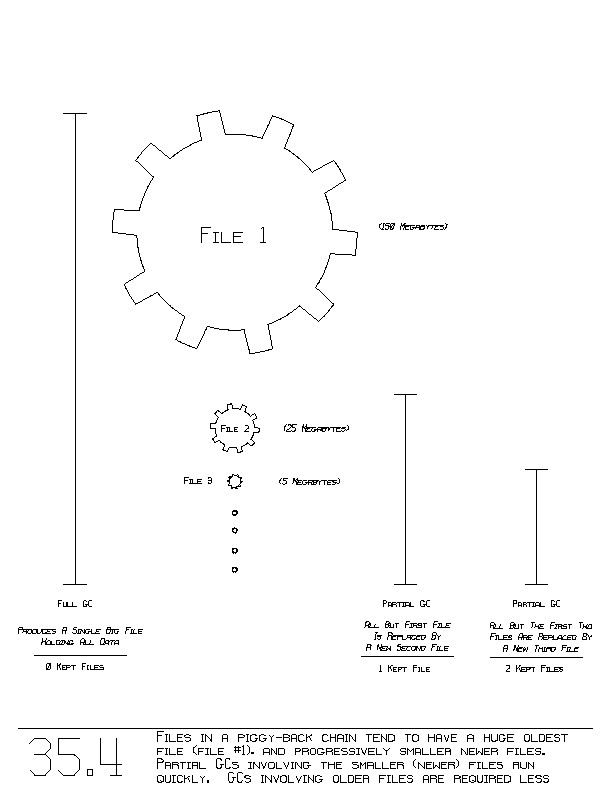 Figure 35.4 illustrates the most effective use of the garbage
collection of VM files. The big, first file, the big gear, revolves
slowly, as it is garbage collected the ~least often. When we say
that the big file is garbage collected, we mean that it and all its
more recent piggy-backed files are given a full GC, rendering ~one big
file.
Next in the piggy-back chain is the second largest file. It may be
garbage collected more often, as a partial GC. This GC replaces
all but the first file with a new, single second file. The second
file and all those piggy-backed off of it, are rendered as a new
~second file that represents everything not in the first file. More
and more recent VM files may be garbage collected even more often, but
each GC here consumes very little time.
BOX: Why is a partial garbage collection significantly
BOX: cheaper than a full garbage collection?
BOX:
BOX: Why can trips thru the older, kept VM files be avoided
BOX: altogether?
BOX:
BOX: What extra roots are considered?
BOX:
BOX: Why must they be considered?
BOX:
BOX: Can a partial GC retain some garbage?
Figure 35.4 illustrates the most effective use of the garbage
collection of VM files. The big, first file, the big gear, revolves
slowly, as it is garbage collected the ~least often. When we say
that the big file is garbage collected, we mean that it and all its
more recent piggy-backed files are given a full GC, rendering ~one big
file.
Next in the piggy-back chain is the second largest file. It may be
garbage collected more often, as a partial GC. This GC replaces
all but the first file with a new, single second file. The second
file and all those piggy-backed off of it, are rendered as a new
~second file that represents everything not in the first file. More
and more recent VM files may be garbage collected even more often, but
each GC here consumes very little time.
BOX: Why is a partial garbage collection significantly
BOX: cheaper than a full garbage collection?
BOX:
BOX: Why can trips thru the older, kept VM files be avoided
BOX: altogether?
BOX:
BOX: What extra roots are considered?
BOX:
BOX: Why must they be considered?
BOX:
BOX: Can a partial GC retain some garbage?