CHAPTER 34
VARIABLE-SIZED MEMORY MANAGEMENT
We consider automatic memory management for blocks of different sizes.
This form of memory management is more expensive than that for fixed-
sized blocks. Ideally, both forms of memory management would be
present. Very small blocks would come from fixed-sized block space.
~Lists are ideally implemented by our 8-byte fixed-sized blocks.
Records and arrays on the other hand, with their random accessiblity,
would be implemented by larger blocks, from the variable-sized block
space
34.1
Non-Copying Memory Management
One could extend our fixed-sized memory management to apply to
variable-sized blocks. Imagine a free list consisting of blocks of
different sizes. The added complexity here occurs when one wants a
new block of some given size. The free list must now be ~searched
in order to find a block of the desired size. This can be expensive
when compared to our old way of taking always the first block off the
free list.
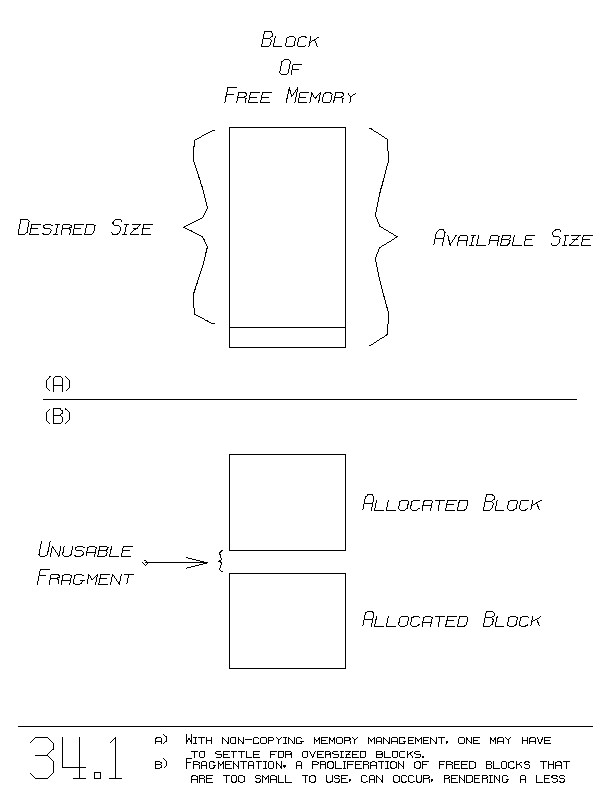 In searching the free list, one could procede in two ways. You can
search either for a block whose size matches exactly the desired size,
or stop as soon as any block large enough is found. If an exact size
match can't be found, then we are stuck using a bigger block (figure
34.1(a)).
The remainder of the bigger block, after claiming the portion of
desired size, becomes a smaller block that goes back onto the free
list. Upon repeated requests for blocks, the free list may wind up
containing many small blocks, most of which might be too small to
satisfy subsequent requests for blocks. The proliferation of small
blocks leaves memory ~fragmented (figuve 34.1(b)).
The fragmentation of memory can render the following situation. A
block allocation can fail by not finding any block big enough. Yet,
not all of memory is in use. The fragments are unusable.
We won't pursue this scheme.
34.2
Copying Memory Management
To rid ourselves of fragmentation, we can envision ~moving blocks
closer together, so as to eliminate all fragments. This moving is
refered to as ~copying.
As in our simplest memory management scheme, we always allocate a new
block off the top of memory. This way, we get a block exactly of the
desired size. When the end of memory is reached, we perform garbage
collection. As before, we ~mark all blocks in use by following all
pointers. Once the used blocks are detected, we move all blocks
downward in memory, so that all blocks in use are compressed into a
continguous chunk at the bottom of memory.
This leaves one contiguous chunk of free space at the top of memory.
We then allocate blocks from there, as before. No free
list is required, just a pointer to the first bin of the free space.
The two new expenses in this new scheme are the ~copying, and the
~translation of addresses. The copying is present of course to avoid
fragmentation. Once blocks have been moved, existing pointers to the
blocks cease to be correct. A pointer pointing to a given block must
be changed so as to continue to point to the block at its new
residence.
BOX: What's the difference between copying and non-copying
BOX: garbage collection?
BOX:
BOX: What advantages does copying offer?
BOX:
BOX: What expenses are new, above and beyond our original
BOX: fixed-sized block garbage collection cost?
34.2.1
A Format For Variable Sized Blocks
In searching the free list, one could procede in two ways. You can
search either for a block whose size matches exactly the desired size,
or stop as soon as any block large enough is found. If an exact size
match can't be found, then we are stuck using a bigger block (figure
34.1(a)).
The remainder of the bigger block, after claiming the portion of
desired size, becomes a smaller block that goes back onto the free
list. Upon repeated requests for blocks, the free list may wind up
containing many small blocks, most of which might be too small to
satisfy subsequent requests for blocks. The proliferation of small
blocks leaves memory ~fragmented (figuve 34.1(b)).
The fragmentation of memory can render the following situation. A
block allocation can fail by not finding any block big enough. Yet,
not all of memory is in use. The fragments are unusable.
We won't pursue this scheme.
34.2
Copying Memory Management
To rid ourselves of fragmentation, we can envision ~moving blocks
closer together, so as to eliminate all fragments. This moving is
refered to as ~copying.
As in our simplest memory management scheme, we always allocate a new
block off the top of memory. This way, we get a block exactly of the
desired size. When the end of memory is reached, we perform garbage
collection. As before, we ~mark all blocks in use by following all
pointers. Once the used blocks are detected, we move all blocks
downward in memory, so that all blocks in use are compressed into a
continguous chunk at the bottom of memory.
This leaves one contiguous chunk of free space at the top of memory.
We then allocate blocks from there, as before. No free
list is required, just a pointer to the first bin of the free space.
The two new expenses in this new scheme are the ~copying, and the
~translation of addresses. The copying is present of course to avoid
fragmentation. Once blocks have been moved, existing pointers to the
blocks cease to be correct. A pointer pointing to a given block must
be changed so as to continue to point to the block at its new
residence.
BOX: What's the difference between copying and non-copying
BOX: garbage collection?
BOX:
BOX: What advantages does copying offer?
BOX:
BOX: What expenses are new, above and beyond our original
BOX: fixed-sized block garbage collection cost?
34.2.1
A Format For Variable Sized Blocks
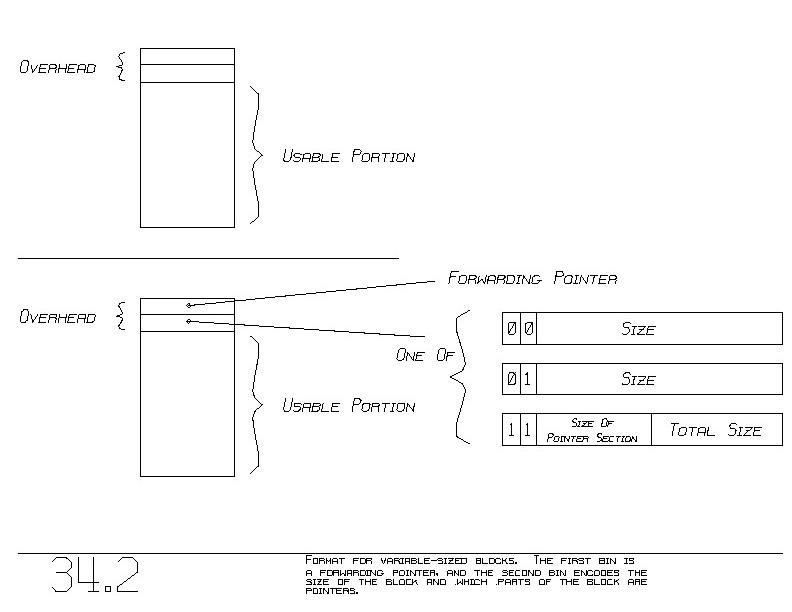 We introduce two bins of overhead into each block (figure 34.2(a)).
The first bin will be used to assist in the translation of pointers,
which is required of course after moving the blocks. This bin is
called the ~forwarding ~pointer. We will return to this bin later.
The second bin holds basically the ~size of the block. The size is
used when we ultimately move the block. It also indicates where in
memory the next block, beyond ours, resides.
There are three different representations for the second bin
(figure 34.2(b)). We have to know which bins in the block are pointers
and which are not. We need this when MARK follows all ~pointers to
discover all blocks in use.
The first format, the "00" case, indicates that there are ~no pointers
in the block. The second format, the "01" case, indicates that ~all
bins in the block are pointers. These two forms implement ~arrays,
where all elements (bins) in the array are of the same type. The
~element ~type of the array dictates which of these formats are used.
The distinction here is similar to that made between our P-block and
D-block.
The third format is for blocks that contain both pointers and non-
pointers. First of all, we insist that all pointers appear ~first,
and all non-pointers appear second. We call these two sections the
~pointer ~section and the ~non-pointer ~section. The format of the
second bin, the size bin, is the third shown. It contains the size
of the pointer section and the total size of the block.
Blocks that include both pointers and non-pointers are useful for
~records, where some components of the record are of types represented
by pointers and others are of non-pointer types. The compiler, behind
the programmer's back, can vary the order of the components so that
all pointer components appear first.
The main use of this mixed-mode block is records. The total number of
bins in the block is small. It is merely the number of components in
the record. This relatively small size allows us to represent the size
in only half a bin (say 15 bits). Records having more than 32000
components are unheard of.
Keep in mind that all pointers to blocks point to the ~first ~bin in
the block.
34.3
The Four Phases Of Variable-Sized Block Memory Management
Although disk-residency can easily be made to work with variable-sized
blocks, we ignore the disk for now. The following thus replaces the
~mark and the ~sweep phases. It may be easiest to think of this
endeavor as extending our simple garbage collection method, which had
only the mark and sweep phases.
The four phases required for variable-sized memory management are:
1) ~Mark all reachable blocks.
2) ~Plan the whereabouts of blocks' new residences
3) ~Translate all pointers
4) ~Move blocks to their new residences.
The first phase is familiar.
34.3.1
Phase 1 - Marking
We mark all reachable blocks like we did before. Now, however, some
pointers can point to variable-sized blocks. We mark a variable-
sized block exactly as we mark any other block. (The mark bit resides
in one of the two overhead bins). Upon marking a variable-sized
block, we go on to mark all blocks referenced by pointers in that
block. The second overhead bin tells us which bins in the block are
pointers. We follow those.
34.3.2
Phase 2 - Planning New Residences
We now pretend to move the blocks. Actually, we merely plan where
each block will reside after compaction (moving).
We introduce two bins of overhead into each block (figure 34.2(a)).
The first bin will be used to assist in the translation of pointers,
which is required of course after moving the blocks. This bin is
called the ~forwarding ~pointer. We will return to this bin later.
The second bin holds basically the ~size of the block. The size is
used when we ultimately move the block. It also indicates where in
memory the next block, beyond ours, resides.
There are three different representations for the second bin
(figure 34.2(b)). We have to know which bins in the block are pointers
and which are not. We need this when MARK follows all ~pointers to
discover all blocks in use.
The first format, the "00" case, indicates that there are ~no pointers
in the block. The second format, the "01" case, indicates that ~all
bins in the block are pointers. These two forms implement ~arrays,
where all elements (bins) in the array are of the same type. The
~element ~type of the array dictates which of these formats are used.
The distinction here is similar to that made between our P-block and
D-block.
The third format is for blocks that contain both pointers and non-
pointers. First of all, we insist that all pointers appear ~first,
and all non-pointers appear second. We call these two sections the
~pointer ~section and the ~non-pointer ~section. The format of the
second bin, the size bin, is the third shown. It contains the size
of the pointer section and the total size of the block.
Blocks that include both pointers and non-pointers are useful for
~records, where some components of the record are of types represented
by pointers and others are of non-pointer types. The compiler, behind
the programmer's back, can vary the order of the components so that
all pointer components appear first.
The main use of this mixed-mode block is records. The total number of
bins in the block is small. It is merely the number of components in
the record. This relatively small size allows us to represent the size
in only half a bin (say 15 bits). Records having more than 32000
components are unheard of.
Keep in mind that all pointers to blocks point to the ~first ~bin in
the block.
34.3
The Four Phases Of Variable-Sized Block Memory Management
Although disk-residency can easily be made to work with variable-sized
blocks, we ignore the disk for now. The following thus replaces the
~mark and the ~sweep phases. It may be easiest to think of this
endeavor as extending our simple garbage collection method, which had
only the mark and sweep phases.
The four phases required for variable-sized memory management are:
1) ~Mark all reachable blocks.
2) ~Plan the whereabouts of blocks' new residences
3) ~Translate all pointers
4) ~Move blocks to their new residences.
The first phase is familiar.
34.3.1
Phase 1 - Marking
We mark all reachable blocks like we did before. Now, however, some
pointers can point to variable-sized blocks. We mark a variable-
sized block exactly as we mark any other block. (The mark bit resides
in one of the two overhead bins). Upon marking a variable-sized
block, we go on to mark all blocks referenced by pointers in that
block. The second overhead bin tells us which bins in the block are
pointers. We follow those.
34.3.2
Phase 2 - Planning New Residences
We now pretend to move the blocks. Actually, we merely plan where
each block will reside after compaction (moving).
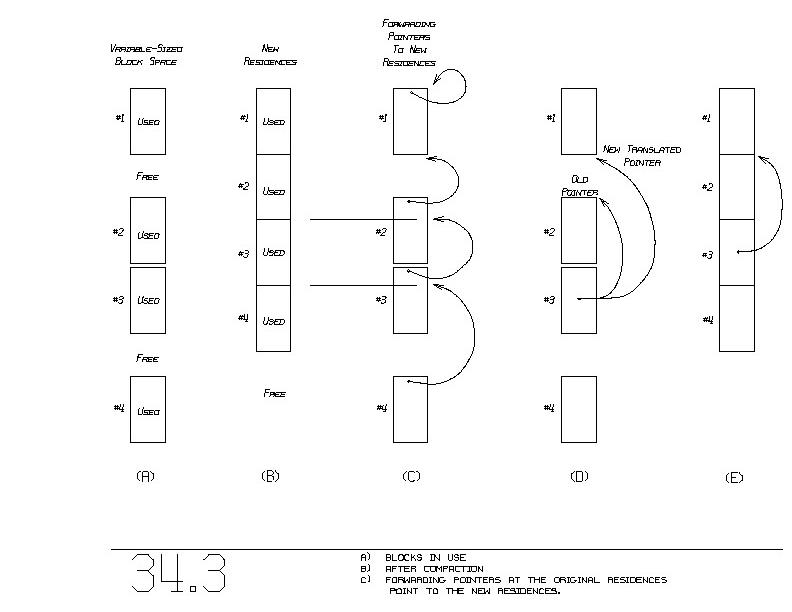 Now that we know the subset of blocks in use (figure 34.3(a)), we can
imagine their compaction (figure 34.3(b)). One simply scans the set
of used blocks, from the bottom to top of memory. We maintain a
special pointer that starts off at the bottom of memory. Upon seeing
each used block, we increment that special pointer by the size of the
block. That pointer indicates the new residence for the ~next used
block.
We make each block's forwarding pointer point to its new residence
(figure 34.3(c)). This will assist us later, when we translate old
pointers into new pointers. One simply takes in a (old) pointer to a
block, fetches that block's forwarding pointer, and voila, we have the
new pointer, pointing to where the this block ~will reside.
34.3.3
Phase 3 - Pointer Translation
We scan once again all used blocks, both fixed-sized and variable-
sized used blocks. We scan linearly from the bottom of memory to the
top. We translate each pointer contained in each block. This is done
by fetching the forwarding pointer, which is found where the given
pointer points. We stuff this new pointer back into the same bin from
which we got the old pointer. This translates all pointers so as to
point now to the referenced block's new address of residence.
For pointers to fixed-sized blocks, which reside in a different space
from variable sized blocks, no translation occurs.
During this scanning of fixed-sized block space, one can implement at
no expense the sweep phase. In common to both the translation of
pointers and the sweep phase is the need to scan fixed-block space
linearly from bottom to top. Encountered unused fixed-sized blocks go
onto the free list, and encountered used blocks get their pointers (to
variable-sized blocks) translated.
34.3.4
Phase 4 - The Moving
Now that the pointers in each block are consistent with where the
blocks ~will reside, we can now move all blocks to their new
residences. We've had to wait this long before moving the blocks
because the previous phase relied on forwarding pointers. Those
forwarding pointers, which reside where old pointers point, had to be
kept intact. Once we move the blocks downward in memory, we will be
writing over those forwarding pointers.
The separate, translation phase had to finish before performing any
block movement.
34.4
The Cost
Of the four phases, the first and third correspond to the mark and
sweep phases of fixed-sized garbage collection. (As indicated earlier,
the sweep for fixed-sized blocks can be implemented at no expense as
part of the translation phase). The new costs are the pointer
translation and the final moving of blocks.
Now that we know the subset of blocks in use (figure 34.3(a)), we can
imagine their compaction (figure 34.3(b)). One simply scans the set
of used blocks, from the bottom to top of memory. We maintain a
special pointer that starts off at the bottom of memory. Upon seeing
each used block, we increment that special pointer by the size of the
block. That pointer indicates the new residence for the ~next used
block.
We make each block's forwarding pointer point to its new residence
(figure 34.3(c)). This will assist us later, when we translate old
pointers into new pointers. One simply takes in a (old) pointer to a
block, fetches that block's forwarding pointer, and voila, we have the
new pointer, pointing to where the this block ~will reside.
34.3.3
Phase 3 - Pointer Translation
We scan once again all used blocks, both fixed-sized and variable-
sized used blocks. We scan linearly from the bottom of memory to the
top. We translate each pointer contained in each block. This is done
by fetching the forwarding pointer, which is found where the given
pointer points. We stuff this new pointer back into the same bin from
which we got the old pointer. This translates all pointers so as to
point now to the referenced block's new address of residence.
For pointers to fixed-sized blocks, which reside in a different space
from variable sized blocks, no translation occurs.
During this scanning of fixed-sized block space, one can implement at
no expense the sweep phase. In common to both the translation of
pointers and the sweep phase is the need to scan fixed-block space
linearly from bottom to top. Encountered unused fixed-sized blocks go
onto the free list, and encountered used blocks get their pointers (to
variable-sized blocks) translated.
34.3.4
Phase 4 - The Moving
Now that the pointers in each block are consistent with where the
blocks ~will reside, we can now move all blocks to their new
residences. We've had to wait this long before moving the blocks
because the previous phase relied on forwarding pointers. Those
forwarding pointers, which reside where old pointers point, had to be
kept intact. Once we move the blocks downward in memory, we will be
writing over those forwarding pointers.
The separate, translation phase had to finish before performing any
block movement.
34.4
The Cost
Of the four phases, the first and third correspond to the mark and
sweep phases of fixed-sized garbage collection. (As indicated earlier,
the sweep for fixed-sized blocks can be implemented at no expense as
part of the translation phase). The new costs are the pointer
translation and the final moving of blocks.
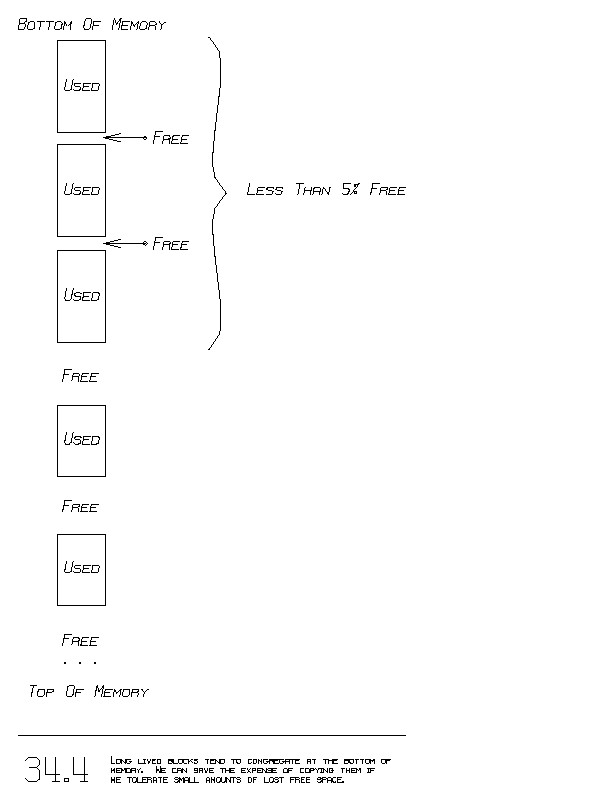 An interesting phenomenon occurs. Since blocks move only downward in
memory, blocks that have been in use for a long time tend to reside
at the bottom of memory. It is often the case the very old blocks
tend to stay in use, whereas a majority of young blocks tend to be
freed soon after their creation. Thus, the bottom of memory tends
to hold only a few free blocks (figure 34.4).
To reduce the cost of moving, one could leave unmoved blocks lower
in memory. As one scans memory from bottom to top, one can keep track
of the percentage of that memory that is free. As long as free memory
makes up only a small fraction, moving can be avoided, at a cost of
~losing only a small part of free memory. Of course, during the
scan from bottom to top, when the percentage free space scanned so
far becomes significant, then it pays to start moving blocks.
This optimization occurs during the planning phase (phase 2).
BOX: What are the four phases of variable-sized GC?
BOX:
BOX: Why must all moving be delayed until after all pointer
BOX: translation is done?
BOX:
BOX: Where in memory do older block congregate?
An interesting phenomenon occurs. Since blocks move only downward in
memory, blocks that have been in use for a long time tend to reside
at the bottom of memory. It is often the case the very old blocks
tend to stay in use, whereas a majority of young blocks tend to be
freed soon after their creation. Thus, the bottom of memory tends
to hold only a few free blocks (figure 34.4).
To reduce the cost of moving, one could leave unmoved blocks lower
in memory. As one scans memory from bottom to top, one can keep track
of the percentage of that memory that is free. As long as free memory
makes up only a small fraction, moving can be avoided, at a cost of
~losing only a small part of free memory. Of course, during the
scan from bottom to top, when the percentage free space scanned so
far becomes significant, then it pays to start moving blocks.
This optimization occurs during the planning phase (phase 2).
BOX: What are the four phases of variable-sized GC?
BOX:
BOX: Why must all moving be delayed until after all pointer
BOX: translation is done?
BOX:
BOX: Where in memory do older block congregate?